I was wondering what happens when you initialize your module....type in insmod module_name.ko.
Most of the code paths in the kernel run as function pointers. You will be tracing some source code and then suddenly there seems to be no direct function call being made, but suddenly the execution returns to the same place. This is where magic happens when function pointers are used.
So, If you are saying what happens when I insert my module, How does the kernel keep track of my custom functions (open, close, read, write, ioctl etc etc).
So the fact is that we as mere mortals are not doing anything extraordinary when we write module operations functions. We are simply attaching our functions read, write.... to a template of module operations.
This kind of framework is essential for the kernel to manage each module operation successfully.
#ifndef MODULE
**
* module_init() - driver initialization entry point
* @x: function to be run at kernel boot time or module insertion
*
* module_init() will either be called during do_initcalls() (if
* builtin) or at module insertion time (if a module). There can only
* be one per module.
*/
#define module_init(x) __initcall(x);
As you can see above this module_init() will be called wither during do_initcalls()....what does he mean, so essentially module_init() is going to register our init function in an array of function pointers. the do_initcalls() is going to call one by one depending on the order and dependencies, function from this array of function pointers (please excuse my english).
#define __initcall(fn) device_initcall(fn)
#define device_initcall(fn) __define_initcall(fn, 6)
/* initcalls are now grouped by functionality into separate
* subsections. Ordering inside the subsections is determined
* by link order.
* For backwards compatibility, initcall() puts the call in
* the device init subsection.
*
* The `id' arg to __define_initcall() is needed so that multiple initcalls
* can point at the same handler without causing duplicate-symbol build errors.
*/
#define __define_initcall(fn, id) \
static initcall_t __initcall_##fn##id __used \
__attribute__((__section__(".initcall" #id ".init"))) = fn; \
LTO_REFERENCE_INITCALL(__initcall_##fn##id)
This bold is one statement.
static initcall_t __initcall_##fn##id __used __attribute__((__section__(".initcall" #id ".init"))) = fn;
typedef int (*initcall_t)(void);
as you can see the initcall_t is a function pointer.
Most of the code paths in the kernel run as function pointers. You will be tracing some source code and then suddenly there seems to be no direct function call being made, but suddenly the execution returns to the same place. This is where magic happens when function pointers are used.
So, If you are saying what happens when I insert my module, How does the kernel keep track of my custom functions (open, close, read, write, ioctl etc etc).
So the fact is that we as mere mortals are not doing anything extraordinary when we write module operations functions. We are simply attaching our functions read, write.... to a template of module operations.
This kind of framework is essential for the kernel to manage each module operation successfully.
#ifndef MODULE
**
* module_init() - driver initialization entry point
* @x: function to be run at kernel boot time or module insertion
*
* module_init() will either be called during do_initcalls() (if
* builtin) or at module insertion time (if a module). There can only
* be one per module.
*/
#define module_init(x) __initcall(x);
As you can see above this module_init() will be called wither during do_initcalls()....what does he mean, so essentially module_init() is going to register our init function in an array of function pointers. the do_initcalls() is going to call one by one depending on the order and dependencies, function from this array of function pointers (please excuse my english).
#define __initcall(fn) device_initcall(fn)
#define device_initcall(fn) __define_initcall(fn, 6)
/* initcalls are now grouped by functionality into separate
* subsections. Ordering inside the subsections is determined
* by link order.
* For backwards compatibility, initcall() puts the call in
* the device init subsection.
*
* The `id' arg to __define_initcall() is needed so that multiple initcalls
* can point at the same handler without causing duplicate-symbol build errors.
*/
#define __define_initcall(fn, id) \
static initcall_t __initcall_##fn##id __used \
__attribute__((__section__(".initcall" #id ".init"))) = fn; \
LTO_REFERENCE_INITCALL(__initcall_##fn##id)
This bold is one statement.
static initcall_t __initcall_##fn##id __used __attribute__((__section__(".initcall" #id ".init"))) = fn;
typedef int (*initcall_t)(void);
as you can see the initcall_t is a function pointer.

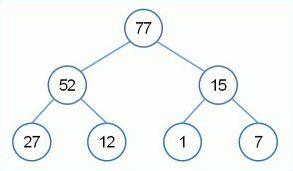 The root always holds the max value
The root always holds the max value