Once again a joy ride of a roller coaster that is the Linux kernel.
What happens when you sleep in the kernel. You here is the process context code that has either voluntarily relinquished the CPU or because it was doing a blocking call.
What happens when you sleep in the kernel. You here is the process context code that has either voluntarily relinquished the CPU or because it was doing a blocking call.
/** 75 * mutex_lock - acquire the mutex 76 * @lock: the mutex to be acquired 77 * 78 * Lock the mutex exclusively for this task. If the mutex is not 79 * available right now, it will sleep until it can get it. 80 * 81 * The mutex must later on be released by the same task that 82 * acquired it. Recursive locking is not allowed. The task 83 * may not exit without first unlocking the mutex. Also, kernel 84 * memory where the mutex resides must not be freed with 85 * the mutex still locked. The mutex must first be initialized 86 * (or statically defined) before it can be locked. memset()-ing 87 * the mutex to 0 is not allowed. 88 * 89 * ( The CONFIG_DEBUG_MUTEXES .config option turns on debugging 90 * checks that will enforce the restrictions and will also do 91 * deadlock debugging. ) 92 * 93 * This function is similar to (but not equivalent to) down(). 94 */ 95 void __sched mutex_lock(struct mutex *lock) 96 { 97 might_sleep(); //---> Just for Debugging. 98 /* 99 * The locking fastpath is the 1->0 transition from 100 * 'unlocked' into 'locked' state. 101 */ 102 __mutex_fastpath_lock(&lock->count, __mutex_lock_slowpath); 103 mutex_set_owner(lock); 104 } 105 106 EXPORT_SYMBOL(mutex_lock);
Ingo Molnar's function header sums it up.
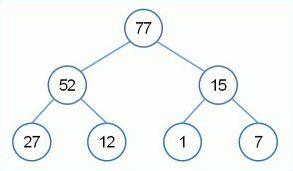 The root always holds the max value
The root always holds the max value